
L’architecture orientée événements (Event-Driven Architecture, EDA) m’est fréquemment présentée comme une forme d’idéal conceptuel, le graal, apte à répondre avec élégance aux enjeux d’asynchronisme et de traitement en temps réel.
D’expérience, ces solutions dissimulent des complexités fonctionnelles, techniques et organisationnelles susceptibles de compromettre la viabilité opérationnelle d’un système, c’est ce que je vais m’atteler à démontrer dans cet article. Sans prétendre à l’exhaustivité de ce sujet, je souhaite attirer l’attention sur quelques-uns des problèmes structurels qu’il soulève.

Tri du courrier au Bureau Central de l’Hôtel des Postes – Rue du Louvre à Paris – 1923
Pour rappel lorsque l’on parle d’EDA, on évoque un modèle où les services n’interagissent pas par appels directs mais par publication et abonnement à des événements via un intermédiaire (broker), plutôt que par des appels de méthodes synchrones comme avec gRPC (qui au passage, donne l’illusion que le service distant est une simple classe locale, avec des méthodes qu’on peut appeler directement, mais derrière lesquelles il est bien question de sérialisation, de transport réseau, de désérialisation…).
En EDA, on cherche au contraire à décorréler les producteurs (producers) et les consommateurs (consumers) d’information. On dit qu’on limite le couplage (le degré de dépendance entre les composants).
Cette notion de couplage pourrait faire l’objet d’un article dédié, puisqu’il existe de nombreux types de couplages:
Couplage temporel : les deux composants doivent être disponibles simultanément pour que l’interaction aboutisse. C’est typiquement le cas dans les architectures synchrones où un service ne peut poursuivre son exécution tant qu’il n’a pas reçu la réponse du service distant.
Couplage technique : un composant doit connaître la localisation exacte de l’autre (adresse réseau, nom de service…). On a donc une dépendance explicite à l’infrastructure, car un composant doit connaître où et comment joindre un autre composant. Cette dépendance peut être atténuée, mais pas entièrement éliminée, grâce à des solutions comme le service discovery, proxies, DNS, service meshes qui abstraient l’infrastructure sous-jacente.
Couplage structurel : les composants partagent et dépendent d’un contrat de données commun, strictement défini (comme un schéma Protobuf, OpenAPI Spec…). Toute évolution de ce contrat doit être soigneusement gérée des deux côtés.
Couplage sémantique : au-delà de la forme des données, les composants sont liés par une compréhension commune du sens métier. Par exemple, si un composant interprète un message comme une commande à exécuter, il doit en comprendre les implications métier, ce qui complexifie son remplacement ou sa réutilisation. Je vais détailler un peu plus cette section, car d’expérience elle est moins bien comprise, et souvent oubliée dans la modélisation. Par exemple, je dispose d’une ressource de type machine virtuelle (VM), à laquelle sont associées certaines propriétés, comme une quantité de mémoire (RAM). Mon système doit être en mesure de déterminer s’il peut provisionner cette VM en fonction de la RAM disponible dans le cluster, tout en vérifiant que les quotas sont respectés (la notion de RAM pourrait être représentée explicitement dans le service de quotas). On se retrouve dans le cas où le couplage sémantique est fort, les consommateurs encodent une compréhension implicite des types et intentions métier. La notion de RAM dépend fortement du contexte sémantique, il pourrait s’agir d’un acronyme métier, ou bien dans notre contexte de la mémoire vive. Sans contexte explicite, des agents différents peuvent interpréter le terme de RAM de façons incompatibles.
C’est précisément pour réduire ce couplage sémantique que je souhaite introduire la notion d’ontologie. Une ontologie, dans ce contexte, est une modélisation explicite et partagée des concepts métiers, de leurs relations et de leurs significations. En fournissant un vocabulaire formalisé, compréhensible par les humains et interprétable par les machines.
Une ontologie permet aux composants de s’accorder sur le sens des messages sans dépendre d’implémentations spécifiques. L’ontologie permet donc à des composants hétérogènes, potentiellement conçus indépendamment, de raisonner sur les événements qu’ils échangent avec une compréhension commune, mais découplée de leur logique métier interne. On renforce ainsi avec une ontologie l’interopérabilité et on ouvre la voie à des formes plus intelligentes de traitement comme l’inférence ou la validation sémantique. Ce type d’approche trouve des applications concrètes.
À NumSpot, on utilise une modélisation de type Relationship-based Access Control (ReBAC), l’autorisation d’un accès ne repose plus uniquement sur des rôles ou des attributs statiques, mais sur une topologie de relations explicites entre entités (utilisateurs, ressources, organisations…). C’est un modèle que nous pourrions modéliser sous forme ontologique:
@prefix : <http://example.org/ontology#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
### Classes
:User a owl:Class .
:Project a owl:Class .
:CloudResource a owl:Class .
### Sous‐classes de ressources cloud
:VM a owl:Class ; rdfs:subClassOf :CloudResource .
:Bucket a owl:Class ; rdfs:subClassOf :CloudResource .
:Database a owl:Class ; rdfs:subClassOf :CloudResource .
### Relations (Object Properties)
:isMemberOf a owl:ObjectProperty ;
rdfs:domain :User ;
rdfs:range :Project .
:owns a owl:ObjectProperty ;
rdfs:domain :Project ;
rdfs:range :CloudResource .
:canAccess a owl:ObjectProperty ;
rdfs:domain :User ;
rdfs:range :CloudResource .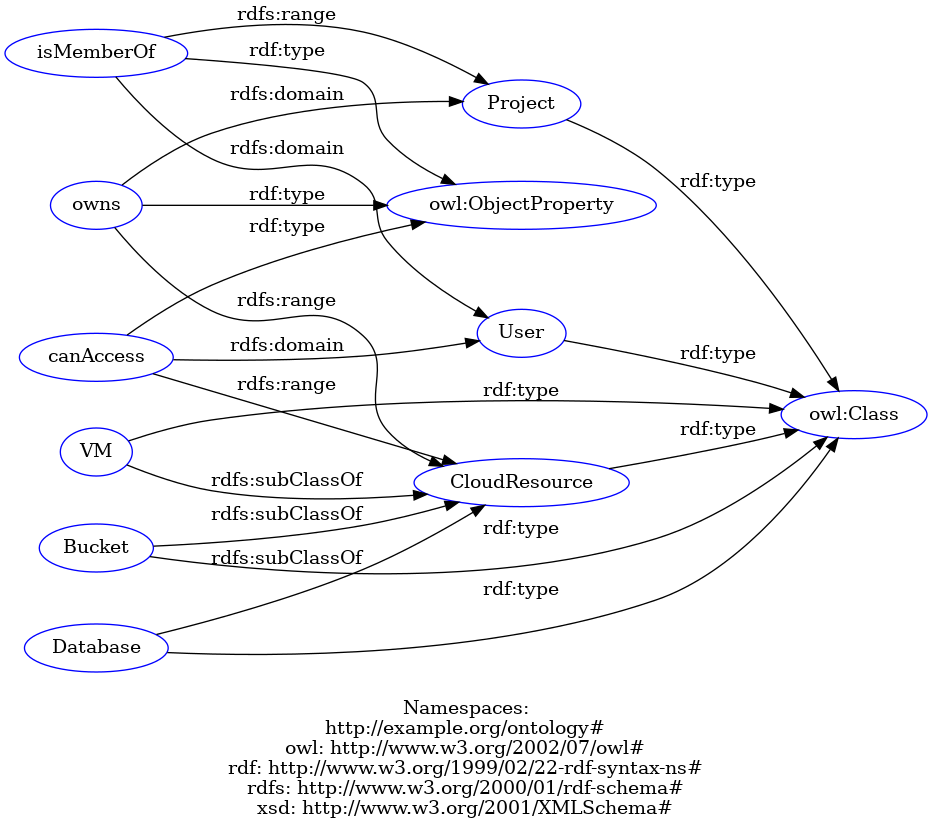
Il nous est ensuite possible de consommer cette ontologie le SWRL (Semantic Web Rule Language)
Si un individu ?u est membre (:isMemberOf) d’un projet ?p
et ce même projet ?p possède (:owns) une ressource ?r,
alors cet individu ?u peut accéder (:canAccess) à la ressource ?r
@prefix swrl: <http://www.w3.org/2003/11/swrl#> .
@prefix swrlv: <http://www.w3.org/2003/11/swrl-variable#> .
:RuleBasicAccess
a swrl:Imp ;
swrl:antecedent (
[ a swrl:IndividualPropertyAtom ;
swrl:propertyPredicate :isMemberOf ;
swrl:argument1 swrlv:?u ;
swrl:argument2 swrlv:?p ]
[ a swrl:IndividualPropertyAtom ;
swrl:propertyPredicate :owns ;
swrl:argument1 swrlv:?p ;
swrl:argument2 swrlv:?r ]
) ;
swrl:consequent (
[ a swrl:IndividualPropertyAtom ;
swrl:propertyPredicate :canAccess ;
swrl:argument1 swrlv:?u ;
swrl:argument2 swrlv:?r ]
) .Dans notre inventaire de ressources, nous avons introduit une modélisation ontologique afin de représenter de manière formelle et exploitable les composants instanciés permettant de typer les relations entre composants.
Cette modélisation nous permet de naviguer par concepts métiers plutôt que par identifiants techniques, de regrouper dynamiquement les ressources en fonction de leur rôle, de leur criticité ou de leur appartenance à un service. Avec cette approche on peut exprimer des règles de gouvernance de façon déclarative: “les ressources taguées ‘confidential’ ne doivent jamais être déployées hors d’une zone de sécurité restreinte”. Ces règles peuvent ensuite être automatiquement évaluées par des moteurs d’inférence sémantique. On peut également s’en service comme une couche d’abstraction pour modéliser un système multi-cloud…. Bref, vous l’aurez compris, on se retrouve avec une infinité de possibilités. Je peux vous conseiller ce livre pour aller plus loi: Python et les ontologies, ou peut-être un prochain article sur le sujet.
Il me semblait important de m’attarder un peu sur les différentes formes de couplage, car elles jouent un rôle clef dans les architectures orientées événements. Comprendre où et comment ces couplages se manifestent permet non seulement d’en évaluer les impacts sur l’évolutivité du système, mais aussi d’identifier les bons leviers pour les atténuer. Cela dit, d’expérience il est parfois préférable de maintenir intentionnellement un certain niveau de couplage, lorsqu’il apporte de la clarté ou de la simplicité, plutôt que de tomber dans une complexité inutile liée à une sur-ingénierie. C’est tout l’objet de mon travail en tant qu’architecte logiciel que d’évaluer ces choix, leurs impacts à l’échelle du système, concevoir des solutions à la fois pérennes, économiquement viables, porteuses de valeur pour les équipes de développement, et conformes aux exigences réglementaires.
Les invariants
Comme paramètres de ces décisions apparaissent les invariants du système, c’est-à-dire des propriétés qui restent toujours vraies.
Si je prends en exemple le pendule simple, dans un système mécanique isolé, l’énergie totale (cinétique + potentielle) reste constante.
Dans un système électrique une batterie ou un composant ne doit jamais excéder une tension limite liée à ses contraintes physiques.
Un système événementiel a également des invariants (liste non exhaustive):
- Les générateurs d’événements ne connaissent ni l’existence des consumers, ni leur nombre, ni leur logique métier; réciproquement les consumers ne connaissent pas les publishers.
- Les dépendances causales (A doit précéder B) sont soit explicitement encodées soit acceptées comme dégradées et gérées par un réordonnancement ou une logique de reprise.
- Dans les EDA avec un modèle de type broadcast (fire and forget), aucun composant ne peut présumer que les événements parviendront dans un ordre déterminé.
- Les consumers doivent être idempotents pour que le retraitement n’altère pas deux fois l’état dans le service
- Les états locaux des différents services convergent vers une vision cohérente
Réflexion autour des invariants
Software is symbolic, abstract, and constrained more by intellectual complexity than by fundamental physical laws
Progress toward an Engineering Discipline of Software – Mary Shaw
D’après Mary Shaw, la complexité d’un système d’information naît donc de couches d’abstractions qui dissimulent la richesse conceptuelle sous-jacente. Les EDA reposent précisément sur ces abstractions, plutôt que de structurer les échanges autour d’appels directs ou de dépendances explicites, elles introduisent des abstractions fortes autour de la notion d’événement. L’interaction devient indirecte, asynchrone, et découplée dans le temps.
Ce modèle ne supprime pas la complexité, il la déplace, au lieu de raisonner en termes de séquences d’appels ou de services interconnectés, on conçoit un système comme un écosystème d’agents réagissant à un flux d’informations. Cela passe par la maîtrise de concepts structurants comme:
- la distinction entre producteurs et consommateurs d’événements, qui introduit un découplage fonctionnel et temporel
- la définition explicite des schémas d’événements, stockés dans un schema registry, qui garantit l’interopérabilité entre les système
- l’usage de modèles sémantiques plus riches, comme les ontologies, pour structurer et exploiter la connaissance portée par ces événements
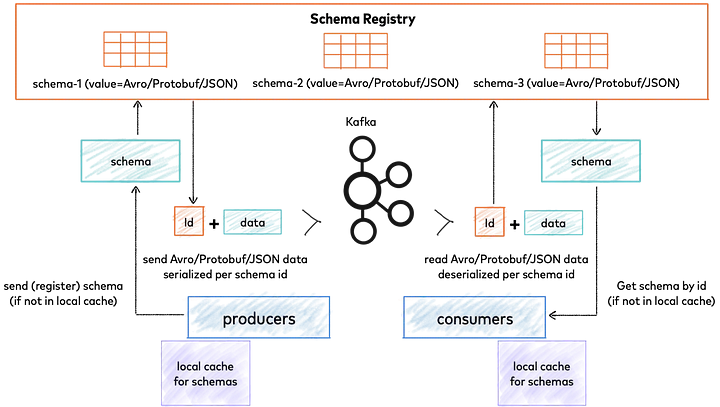
Schema Registry for Confluent Platform
En EDA, on compose des services en les faisant réagir à des événements publiés dans un espace commun via le broker, cette composition n’est pas une abstraction, elle ne masque pas la complexité du système mais la dilue. Puisque j’introduis les notions de composition et d’abstraction je vais les définir en m’appuyant sur les définitions de Gregor Hohpe (cf: Good abstractions are obvious but difficult to find, even in the cloud)
La composition consiste à combiner des composants ou services existants pour former un ensemble plus complexe. L’abstraction, en revanche, vise à masquer la complexité des composants sous-jacents pour offrir une interface plus simple et centrée sur l’intention. Une bonne abstraction permet aux développeurs de se concentrer sur le « quoi » plutôt que sur le « comment ». Par exemple, un service nommé StaticWebsite qui configure automatiquement un bucket S3, un CDN CloudFront et un enregistrement DNS Route 53, permet au développeur de déployer un site statique sans se soucier des détails de configuration de chaque service.
Dans ce contexte, le rôle de l’abstraction n’est pas simplement d’éviter de voir la plomberie, mais d’offrir une interface compréhensible, testable et gouvernable au-dessus d’un maillage distribué et asynchrone (Service A, Service B, Service C…).
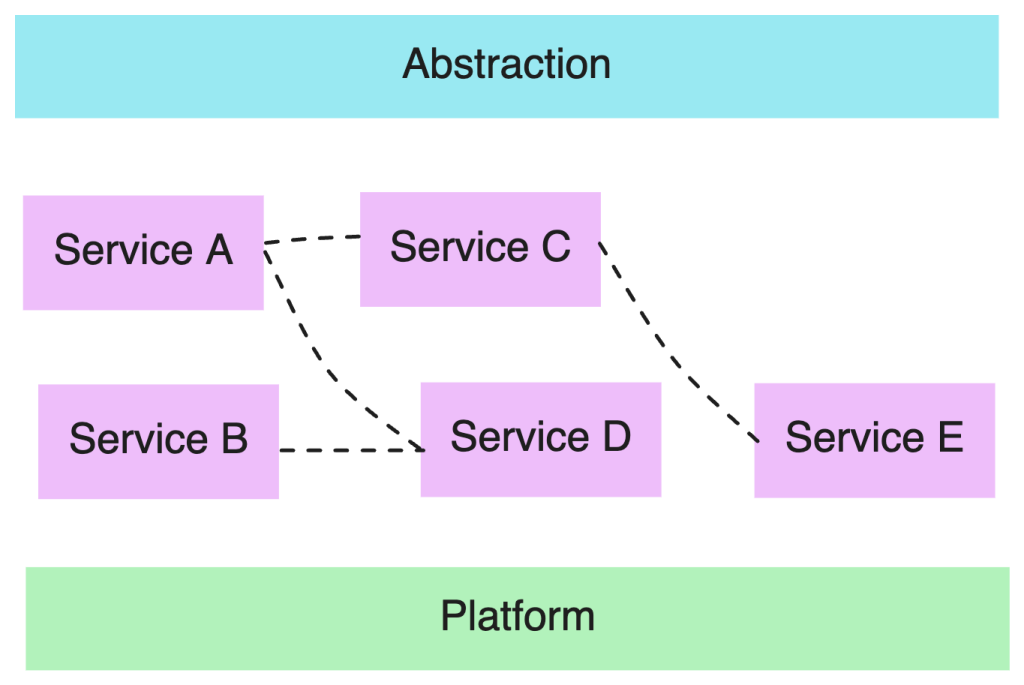
Faire de la composition en branchant un producer et plusieurs consumers via un topic Kafka ne garantit ni simplicité, ni interopérabilité (lignes pointillés sur le schéma ci-dessus). L’abstraction apportée par le broker et les événements, au contraire, vise à réduire la charge cognitive, à rendre les dépendances visibles (même dans un modèle pub/sub), et à exposer avec la bonne granularité les notions métiers. On doit mettre en place certains éléments clefs pour ne pas se retrouver dans un flux d’exécution implicite:
- On peut reconstruire une vue d’ensemble avec de la traçabilité distribuée (correlationId, span context) et rendre explicite le chemin des événements avec des dashboards qui corrèlent logs, métriques et traces).
- On doit typer et versionner les messages avec un contrat d’interface (couplage structurel), avec une spécification formelle des contrats comme proposé par AsyncAPI ou Cloud Events..
Dans cette recherche des bonnes abstractions, on a d’autres facteurs comme l’asynchronisme qui ajoute une dimension temporelle aux messages qui transitent: expiration potentielle des messages, délais de propagation, dépendances implicites entre tâches…
À ces paramètres s’ajoutent des effets combinatoires, l’état partagé n’est plus qu’une illusion avec un broker et on se retrouve à gérer des race conditions (non déterministes) lorsque plusieurs services se mettent à traiter simultanément un même événement. Il nous faut donc jongler avec des erreurs qui peuvent survenir bien après l’émission initiale d’un événement dans un service distant, rendant ardue la façon de propager cette erreur avec son contexte d’exécution. On serait tenté de s’en prémunir avec des tests, mais les stratégies de tests deviennent de plus en plus lourdes, avec des tests en amont de l’émission et de la consommation d’événements, la nécessité de simuler l’injection des messages et les délais de tranmission dans les tests d’intégration…
On glisse vite dans une zone où la complexité théorique si elle n’est pas maitrisée rend le système imprévisible. J’ai naturellement envie de faire le lien avec les automates cellulaires avec lesquels j’ai pu jouer pendant mes années d’études avec une complexité émergente de règles simples. En EDA, il en est de même, des interactions simples entre composants peuvent conduire à des dynamiques complexes et difficiles à prévoir.

Game of Life animation in p5.js. Image courtesy of Hailey Mah
En EDA chaque service, chaque message, chaque schéma d’événement, chaque relation implicite ou transformation potentielle ajoute une nouvelle dimension d’interaction. Au départ, avec 3 ou 4 services, le système reste intelligible.
Plus le système croît avec une explosion des combinatoires, plus la maîtrise du système devient difficile. Les événements devraient idéalement être orthogonaux (indépendants), mais dans la réalité ils interagissent souvent implicitement ou explicitement, ce qui nuit à la modularité, à la compréhension du système. On peut y ajouter une dimension supplémentaire qu’est le facteur humain / organisationnel, qui influencera inévitablement la manière dont les topics sont conçus, nommés et structurés. Comme le souligne la loi de Conway, « tout système conçu par une organisation reflète la structure de communication de cette organisation ». Autrement dit, les frontières techniques, y compris la modélisation des interfaces entre les événements, épouseront presque toujours les silos, les équipes ou les flux de responsabilité existants… Arriver à démêler ça est un travail du quotidien. Dans ce contexte organisationnel, un message que j’aime donc promouvoir est celui de la loi de Brooks:
« Ajouter des personnes à un projet en retard accroît son retard »
La loi de Brooks montre que plus il y a de développeurs, plus il devient difficile de synchroniser les efforts et plus on dérive vers un espace de haute dimension.
Les transformations d’événements (médiateurs, transformations de format, mappings) peuvent devenir complexes, difficiles à maintenir, fragiles si elles ne sont pas correctement abstraites ou documentées. L’empilement de transformations peut provoquer une perte de contexte ou de sémantique, entraînant des bugs difficiles à détecter. Maintenir des invariants métier (cohérence transactionnelle, ordre d’exécution, idempotence des traitements) à travers une architecture distribuée et asynchrone constitue une source de complexité et d’erreurs. C’est ce que l’on appel le fléau de la dimension.

Je ne vois pas beaucoup d’options pour contenir l’entropie du système autres que de:
- Limiter les types d’événements exposés quitte à regrouper des événements à la façon des agrégats en domain driven design pour concevoir des schémas d’événements plus abstraits alignés sur les concepts métiers et non porteurs de détails techniques.
- Enrichir les événements avec des métadonnées contextuelles (pour l’observabilité, ou la sémantique)
Dans certains cas d’usage, l’ordre de consommation des événements n’est pas simplement souhaitable, il est fondamental pour garantir la cohérence métier. Ça implique la mise en place de mécanismes spécifiques de contrôle d’ordonnancement.
Je prends un exemple volontairement simplifié. Un cloud provider souhaite exposer les transitions d’état de ses machines virtuelles via des événements métier structurés :
- VM_CREATED : la machine est provisionnée (réservation de ressources, attribution IP, etc.)
- VM_STARTED : l’hyperviseur confirme que la VM est opérationnelle
- VM_STOPPED : la machine a été arrêtée
Ces événements peuvent être consommés par une variété de services (console d’administration, moteur de facturation, l’IAM pour associer des permissions à la VM…) qui dépendent de la séquence temporelle des états pour raisonner correctement.
Dans ce scénario, l’enchaînement logique attendu est : CREATED → STARTED → STOPPED
Si je m’attarde sur le moteur de facturation comme consumer, la tarification doit être déclenchée au moment où une ressource est réellement active (STARTED) et la clore à l’arrêt (STOPPED).
Dès lors, que se passerait-il si, en raison de désynchronisations ou de latences réseaux, l’ordre effectif reçu par un consommateur était : STOPPED → STARTED → CREATED ?
Cette inversion sémantique rendrait la logique de facturation incohérente. Les opérations de facturation ne sont pas commutatives, elles doivent être appliquées exactement dans la séquence où elles se sont produites. À l’inverse, certains services peuvent très bien vivre avec un flux désordonné. Il n’y a qu’à prendre l’exemple d’un module qui ajoute des labels aux VMs. Le service se contente d’inscrire ou de mettre à jour une métadonnée et n’a pas besoin de connaître l’état précis de la machine.
Pour éviter les doublons, il s’appuie sur une clé d’idempotence (par ex. {aggregateId, eventId}) :
- aggregateId : identifiant stable de la VM, souvent un UUID.
- eventId : identifiant unique de l’événement.
Dès qu’un message portant la même clef est lue par le consumer une seconde fois ou dans le désordre, le service le reconnaît, l’ignore ou le réordonne avec une information temporelle ou un identifiant séquentiel, le résultat final reste correct sans avoir à imposer un ordre global. En synthèse, voici des points de vigilance pour atteindre cet objectif:
- Segmenter le flux global d’événements en partitions logiques par agrégat métier. Les événements d’une même entité seront traités séquentiellement, assurant l’ordre requis localement. Kafka, par exemple, permet ce partitionnement logique garantissant que tous les événements d’un même agrégat arrivent toujours au même consommateur dans le bon ordre.
- Implémenter des mécanismes de tampons (event buffering) pour réorganiser localement les événements selon leur timestamp ou leur numéro de séquence avant traitement.
- Intégrer dans les événéments un mécanisme de timestamp logique (type vector clocks avec un numéro de séquence) permettant aux consommateurs d’établir un ordre causal fiable malgré les aléas réseaux.
On voit bien que pour ce type de cas d’usages, l’utilisation de l’EDA n’est pas optimale, ces points introduisent une certaine complexité opérationnelle. C’est pourquoi, dans les cas où l’ordonnancement des événements est nécessaire pour garantir la cohérence métier, je privilégierais l’usage d’un orchestrateur de workflows (comme Temporal, Camunda, Zeebe, Activiti). En reprenant l’exemple du processus de facturation, l’orchestrateur de workflows permet de décrire, pas à pas, le cycle de vie complet de la machine virtuelle (création, exploitation, arrêt). L’orchestration devient bloquante mais permet au moins de garantir l’intégrité métier en suspendant le passage à l’étape suivante tant que l’action courante n’est pas validée. Contrairement à l’EDA ou le contrôle d’intégrité métier est dispersé, partiellement asynchrone, avec des difficultés à coordonner une compensation globale… La distinction entre orchestration et chorégraphie ouvre un champ de réflexions plus large que celui de l’article, tant en matière de conception que de gouvernance des flux. Il me paraissait intéressant d’introduire cette notion d’orchestrateur pour illustrer avec l’exemple de la facturation que le métier oriente le choix des solutions et des paradigmes.
Complexité opérationnelle
Pour aborder plus finement les enjeux opérationnels liés aux architectures événementielles, je vais dégrossir le fonctionnement interne d’une solution comme Kafka. Pour ça je m’appuie sur son architecture comme point d’ancrage pour la suite de l’article.
Rappels sur les concepts fondamentaux de Kafka
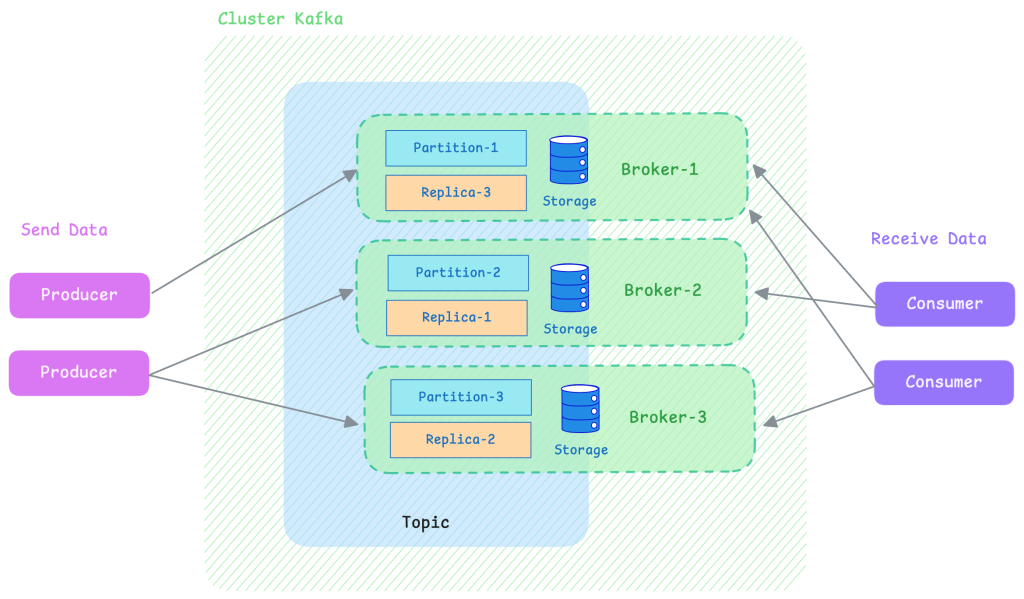
Producteur (Producer)
Composant chargé de publier des messages dans Kafka. Il envoie les données à un ou plusieurs sujets (topics) selon la logique métier.
Consommateur (Consumer)
Composant chargé de lire les messages depuis Kafka et d’exécuter une action en conséquence (stockage, traitement métier, alerte…).
Offset
Chaque consommateur garde la trace de sa position dans une partition (l’offset) pour reprendre la lecture au bon endroit après un redémarrage ou une panne. Ça permet de garantir l’absence de perte de données côté consommateur, tant que les messages sont encore disponibles.
Broker
Un serveur Kafka qui assure le stockage des messages sur disque. Les messages sont conservés pendant une durée de rétention configurable, ce qui permet aux consommateurs de rejouer ou rattraper des messages en cas de besoin.
Cluster Kafka
L’ensemble de plusieurs brokers (et d’autres composants techniques, hors de notre propos ici). Il assure la montée en charge et la haute disponibilité du système.
Topics et Partitions
Les données sont regroupées par topic (description métier). Chaque topic est ensuite divisé en partitions, qui permettent de répartir les données sur plusieurs machines.
Pourquoi des partitions ? Parce qu’il est rarement judicieux de stocker toutes les données sur une seule machine. Les partitions permettent le parallélisme et la scalabilité horizontale.
Leader
Chaque partition a un broker leader, responsable de gérer la partition principale. Kafka maintient également des copies de sauvegarde (réplicas) de chaque partition sur d’autres brokers.
Réplication
Les messages d’une partition sont répliqués sur plusieurs brokers. Ça permet de garantir la tolérance aux pannes :
Que se passe-t-il si un broker tombe ?Un autre broker prend le relais.
Une solution qui a des limites
Couplage entre calcul et stockage
Dans Kafka, chaque broker gère localement ses partitions et les données associées. On se retrouve avec un couplage fort entre la capacité de calcul et le stockage:
- Ajouter un broker impose de redistribuer les partitions, ce qui implique le déplacement potentiellement massif de données
- Le processus de rebalancing est très consommateur en I/O (réseau et disque), long et a un impact sur les performances en production
Coûts élevés liés au stockage et à la réplication
Le modèle de Kafka repose sur un stockage local par partition, avec une réplication par défaut sur trois nœuds. Ce qui implique:
- Des coûts de stockage importants, en particulier avec des disques SSD
- Des surcoûts réseau lorsqu’il s’agit de répliquer les données entre plusieurs availability zones
Lorsqu’on prend en compte la réplication, l’espace libre requis pour garantir la sécurité des opérations, qu’on cherche à augmenter la performance en ayant un choix de stockage qui maximise le nombre d’opérations d’entrée/sortie que le périphérique de stockage peut effectuer en une seconde (IOPS), le coût effectif devient conséquent…
Ajouté à ça la complexité et la lenteur des opérations de rebalancing dans Kafka qui limite la capacité à effectuer du scaling dynamique: https://www.redpanda.com/guides/kafka-performance-kafka-rebalancing On se retrouve donc à devoir sur-provisionner des ressources à l’avance.
Le tiered storage
Le tiered storage a été introduit pour permettre à Kafka de gérer de grands volumes de données tout en réduisant les coûts de stockage. L’idée derrière est de conserver les données récentes (« chaudes ») sur des disques locaux rapides type SSD et de déplacer les données plus anciennes (« froides ») vers des solutions de stockage objet moins coûteuses via du S3, HDFS.
On se retrouve à gérer de nouvelles problématiques. L’intégration d’un second niveau de stockage introduit des points de défaillance supplémentaires avec des problèmes de latence, de cohérence des données ou de connectivité réseau qui peuvent survenir lors de l’accès aux données stockées à distance .
Dans Kafka, la façon dont les messages sont conservés peut être adaptée selon les besoins métier. Trois stratégies principales de rétention sont possibles :
- La rétention infinie qui signifie que tous les messages, y compris les anciennes versions d’une même donnée sont conservés indéfiniment dans les logs. Ça permet de garder un historique complet, mais avec le temps, la taille des fichiers peut finir par saturer l’espace disque.
- La rétention limitée, les messages sont supprimés automatiquement après un certain délai ou lorsque le journal atteint une certaine taille. C’est une stratégie classique qui permet de limiter l’usage du stockage en se séparant de l’exhaustivité de l’historique.
- La compaction de topic, dans ce mode, Kafka conserve uniquement la dernière valeur connue pour chaque clef. Si plusieurs messages concernent la même clef, seule la version la plus récente est conservée. C’est utile lorsqu’on veut maintenir un état à jour par clef, comme un registre avec uniquement les dernières informations, et bien dans Kafka, on ne peut pas utiliser cette stratégie avec du tiered storage.
On voit bien que certaines de ces évolutions introduites pour simplifier l’usage de Kafka, finissent par ajouter une couche de complexité opérationnelle supplémentaire, classiquement en informatique on empile les solutions en créant de nouveaux problèmes jusqu’à se retrouver dans des situations parfois ubuesques. Pour masquer la complexité de bas niveau, on empile des couches d’abstraction… qui génèrent leur propre complexité.
J’ai récemment vu passer la proposition « diskless topics » qui acte le fait que la communauté de Kafka explore des pistes plus radicales (KIP-1150) pour proposer des solutions plus “cloud native”. Cette proposition vise à écrire directement les messages dans un stockage objet en supprimant la dépendance au stockage local et à la réplication entre brokers. Il m’est encore difficile de percevoir clairement ce qui différencie cette approche de celle déjà adoptée par des solutions comme Pulsar…
J’ai trouvé au sujet des lacunes de Kafka un artcle intéressant de Gunnar Morling (ingénieur chez Confluent), dans lequel il partage ses réflexions sur ce que pourrait être Kafka s’il devait être repensé aujourd’hui: What If We Could Rebuild Kafka From Scratch?
D’autres solutions existent comme BufStream, mais comme toute implémentation compatible avec le protocole Kafka, elle hérite de certaines limitations structurelles liées au design initial du système, notamment celles que le KIP-890: Transactions Server-Side Defense vise à corriger, dont a hérité BufStream.
Dans le choix des composants d’infrastructure viennent s’ajouter de nombreuses questions conceptuelles:
- Combien de partitions par topic, et par broker, peut‑on gérer sans saturer la mémoire/CPU ?
- Comment équilibrer les partitions?
- Ai-je la bonne configuration des ACLs pour restreindre l’accès aux topics ?
- Quelles garanties de livraison sont nécessaires (at-most-once, at-least-once, exactly-once) ?
- Comment assurer la persistance en cas de crash (réplication, backups) ?
Conclusion
L’objectif de l’article n’était pas de proscrire l’usage d’un broker, mais de choisir un niveau de sophistication adapté aux besoins, et surtout de traiter explicitement les propriétés critiques du système comme ce qui a été abordé au long de cet article pour nourrir les réflexions. Il existe d’ailleurs plusieurs alternatives à l’approche EDA pour gérer l’asynchronisme.
- Utilisation de callbacks (synchrones différés), le producteur fournit une fonction de rappel au consumer, qui sera appelée ultérieurement.
- Utilisation du polling avec un consumer qui interroge régulièrement une source de données pour récupérer les nouvelles données. Comme ce qui est fait par un consumer d’un broker finalement, mais en allégeant sa charge puisque le broker porte nombre de fonctionnalités: back-pressure, persistance, offset…
- Utilisation de structures partagées en mémoire dans des solutions autonomes, Redis Streams, qui est récemment repassé en open-source (sous licence AGPLv3).
J’en profite pour faire un lien avec mon précédent article qui fait écho à une réflexion plus large sur l’évolution des stratégies open-source: Compte rendu libre au lab.
La solution NATS connait également des discussions agitées en ce moment: Looking Ahead with Clarity and Purpose for NATS.io - L’outbox pattern
C’est le modèle métier qui doit guider les choix techniques, et non l’inverse.
Chaque broker, qu’il s’agisse de Kafka, Nats, Pulsar, Bufstream… propose des abstractions différentes : topics, partitions, transactions… Ces choix techniques sont importants, bien sûr, mais ils doivent rester au service du domaine et non l’inverse.
Ce qui importe avant tout, c’est de construire des workflows métier clairs et bien modélisés, de comprendre précisément qui produit quelles données, dans quel but et dans quel contexte. L’approche événementielle n’a de valeur que si elle permet d’exprimer des intentions alignées avec le langage du domaine.
Déployer un broker est à la portée de la plupart des équipes techniques. Ce qui différencie son intégration comme élément pertinent de l’architecture, c’est la capacité des équipes à introduire une solution cohérente avec les enjeux métiers, et d’éviter les surcomplexifications inutiles, à garder à l’esprit que chaque abstraction introduite a un coût, qu’elle soit technique, opérationnelle ou cognitive.
Je terminerai sur cette référence littéraire au livre À bouts de flux, qui nous rappelle à quel point nos systèmes prétendument « résilients » reposent en réalité sur un enchevêtrement de dépendances fragiles, souvent invisibles. Le numérique, que nous percevons comme immatériel, autonome, est indissociable d’un réseau d’infrastructures physiques, électriques, logistiques, énergétiques, dont la moindre défaillance peut entraîner des effets en cascade.
À mon sens, la réflexion peut, naturellement, être étendue aux architectures orientées événements et plus largement à la façon dont nous concevons des systèmes aujourd’hui.