
Event-Driven Architecture (EDA) is often presented to me as a kind of conceptual ideal, the holy grail capable of elegantly addressing the challenges of asynchrony and real-time processing.
In my experience, such solutions tend to conceal functional, technical and organisational complexities that can jeopardise the operational viability of a system. That’s what I aim to highlight in this article. Without claiming to be exhaustive on the topic, I’d like to draw attention to some of the structural issues it raises.

Mail sorting at the Central Office of the Hôtel des Postes – Rue du Louvre, Paris – 1923
To recap, when we talk about EDA, we refer to a model where services interact not through direct calls, but via the publication and subscription of events through a broker. This differs from synchronous method calls like those with gRPC (which, incidentally, can give the illusion that a remote service is just a local class with methods that can be invoked directly, even though what actually happens under the hood is serialisation, network transport, deserialisation, etc.).
In EDA, the goal is instead to decouple the producers and consumers of information. This is commonly described as reducing coupling the degree of dependency between components.
This notion of coupling could merit a dedicated article, as there are several distinct types:
Temporal Coupling: Both components must be available at the same time for the interaction to succeed. This is typically the case in synchronous architectures, where a service cannot proceed until it has received a response from the remote service.
Technical Coupling: A component needs to know the exact location of another (e.g. network address, service name…). This creates an explicit dependency on the infrastructure, since one component must know where and how to reach another. This dependency can be mitigated though not fully eliminated through solutions like service discovery, proxies, DNS or service meshes, which abstract away the underlying infrastructure.
Structural Coupling: Components share and rely on a common, strictly defined data contract (such as a Protobuf schema or an OpenAPI spec). Any change to this contract needs to be carefully managed on both sides.
Semantic Coupling: Beyond the structure of the data, components are tied together through a shared understanding of business meaning. For instance, if a component interprets a message as a command to execute, it must understand its business implications, which makes replacing or reusing that component more complex. I’ll go into a bit more detail on this, as in my experience it’s less well understood and often overlooked during modelling.
Say, for example, I have a virtual machine (VM) resource, which has associated properties such as a memory (RAM) amount. The system needs to be able to determine whether it can provision this VM based on available RAM within the cluster, while also verifying that quota policies are respected (RAM might be explicitly represented in the quota service). We find ourselves in a situation of strong semantic coupling, consumers embed an implicit understanding of business types and intent. The concept of RAM heavily depends on the semantic context: it could be a business-specific acronym, or, in our case, it refers to volatile memory. Without an explicit context, different agents may interpret the term RAM in incompatible ways.
This is precisely why I’d like to introduce the concept of ontology to help reduce semantic coupling. An ontology, in this context, is an explicit and shared model of business concepts, their relationships and meanings providing a formalised vocabulary that is both human-readable and machine-interpretable.
An ontology allows components to agree on the meaning of messages without depending on specific implementations. In doing so, heterogeneous components, potentially developed independently, can reason about the events they exchange with a shared, yet decoupled, understanding of business logic. Ontologies therefore strengthen interoperability and pave the way for more intelligent forms of processing such as inference or semantic validation. This approach has tangible applications.
At NumSpot, we use a Relationship-based Access Control (ReBAC) model, where access authorisation no longer relies solely on static roles or attributes, but on a topology of explicit relationships between entities (users, resources, organisations, etc.). It’s a model we could represent ontologically:
@prefix : <http://example.org/ontology#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
### Classes
:User a owl:Class .
:Project a owl:Class .
:CloudResource a owl:Class .
### Sous‐classes de ressources cloud
:VM a owl:Class ; rdfs:subClassOf :CloudResource .
:Bucket a owl:Class ; rdfs:subClassOf :CloudResource .
:Database a owl:Class ; rdfs:subClassOf :CloudResource .
### Relations (Object Properties)
:isMemberOf a owl:ObjectProperty ;
rdfs:domain :User ;
rdfs:range :Project .
:owns a owl:ObjectProperty ;
rdfs:domain :Project ;
rdfs:range :CloudResource .
:canAccess a owl:ObjectProperty ;
rdfs:domain :User ;
rdfs:range :CloudResource .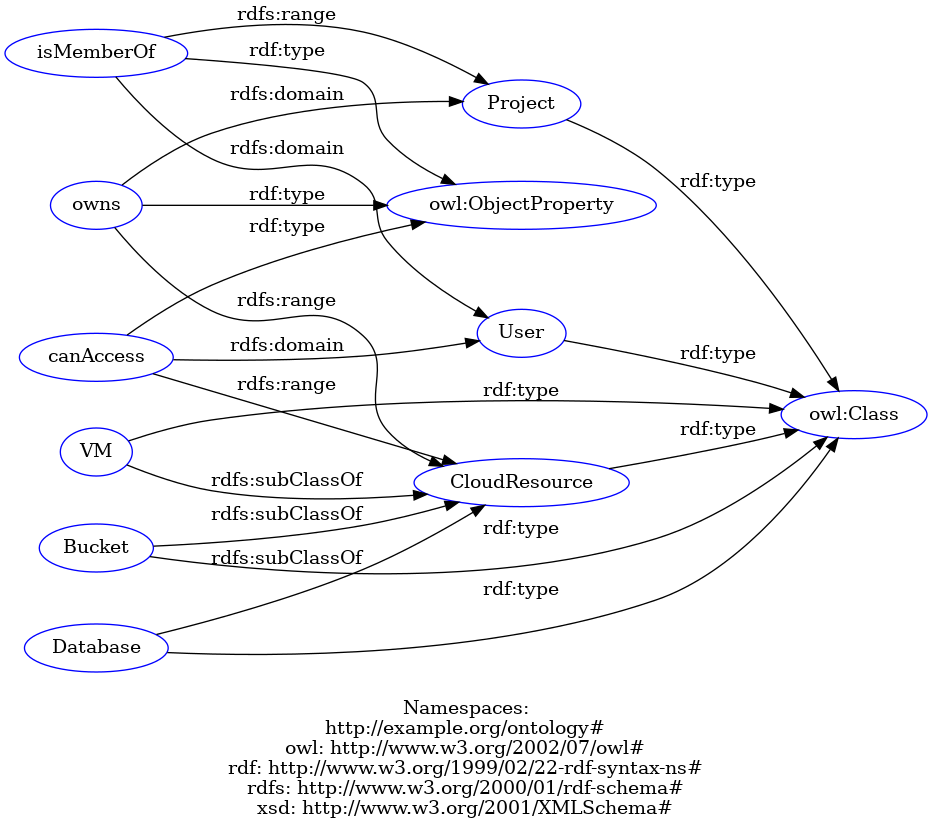
We can then consume this ontology using SWRL (Semantic Web Rule Language)
If an individual ?u is a member (:isMemberOf) of a project ?p,
and that same project ?p owns (:owns) a resource ?r,
then the individual ?u may access (:canAccess) the resource ?r.
In our resource inventory, we introduced an ontological model to formally and operably represent instantiated components, allowing us to type the relationships between them.
This modelling enables us to navigate using business concepts rather than technical identifiers, and to dynamically group resources according to their role, criticality, or service ownership. With this approach, we can express governance rules declaratively, for example: “resources tagged as ‘confidential’ must never be deployed outside a restricted security zone.” These rules can then be automatically evaluated by semantic inference engines.
It can also serve as an abstraction layer for modelling multi-cloud systems… In short, as you’ve probably guessed, this opens up an endless range of possibilities.
If you’re interested in exploring this further, I recommend the book Python and Ontologies, or perhaps a future article on the topic.
I felt it was important to take the time to explore the various forms of coupling, as they play a key role in event-driven architectures. Understanding where and how these couplings appear not only helps to assess their impact on system scalability, but also to identify the right levers to mitigate them. That said, in my experience, it’s sometimes preferable to deliberately maintain a certain level of coupling when it brings clarity or simplicity, rather than to fall into unnecessary complexity through over-engineering. This is exactly what my job as a software architect is about: assessing these trade-offs, evaluating their system-wide impact, and designing solutions that are sustainable, economically viable, valuable to development teams, and compliant with regulatory requirements.
System Invariants
System invariants are key parameters in such decision-making. These are properties that always hold true.
To take a simple analogy, in a basic pendulum within an isolated mechanical system the total energy (kinetic + potential) remains constant.
In an electrical system, a battery or component must never exceed a voltage limit due to its physical constraints.
Similarly, an event-driven system has its own invariants (non-exhaustive list):
- Event producers are unaware of the existence, quantity, or business logic of consumers and vice versa.
- Causal dependencies (A must precede B) must either be explicitly encoded or accepted as potentially degraded and managed via reordering or recovery logic.
- In broadcast-style EDA models (fire-and-forget), no component can assume events will arrive in a specific order.
- Consumers must be idempotent, to ensure that reprocessing does not alter the service state more than once.
- Local states across services should converge toward a consistent overall system view.
Reflection on invariants
Software is symbolic, abstract, and constrained more by intellectual complexity than by fundamental physical laws
Progress toward an Engineering Discipline of Software – Mary Shaw
According to Mary Shaw, the complexity of an information system arises from layers of abstraction that obscure the underlying conceptual richness. EDAs are built precisely on such abstractions. Rather than structuring interactions around direct calls or explicit dependencies, they introduce strong abstractions centred on the notion of events. Interaction becomes indirect, asynchronous, and decoupled in time.
This model does not eliminate complexity it merely relocates it. Instead of reasoning in terms of call sequences or interconnected services, one must design a system as an ecosystem of agents reacting to a stream of information. This requires mastering a number of foundational concepts, such as:
- The distinction between event producers and consumers, which introduces functional and temporal decoupling;
- The explicit definition of event schemas, stored in a schema registry, ensuring interoperability between systems;
- The use of richer semantic models, such as ontologies, to structure and leverage the knowledge embedded in events.
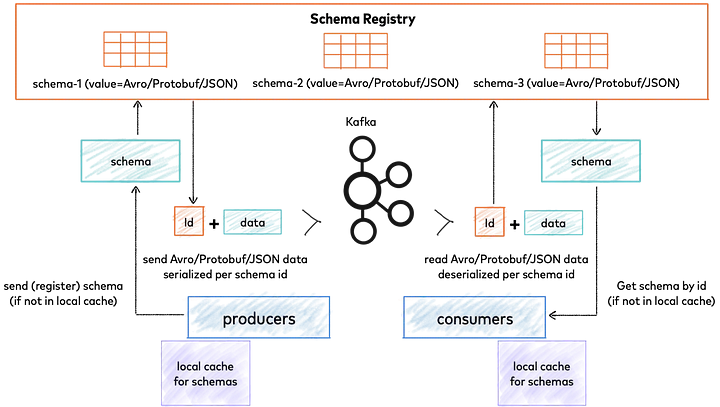
Schema Registry for Confluent Platform
In an EDA, services are composed by making them respond to events published into a shared space via the broker. This composition is not an abstraction it does not conceal the system’s complexity, but rather disperses it.
Since I’m introducing the notions of composition and abstraction, I’ll define them using Gregor Hohpe’s framework (cf. Good abstractions are obvious but difficult to find, even in the cloud).
Composition refers to the act of combining existing components or services to form a more complex whole.
Abstraction, on the other hand, aims to hide the complexity of underlying components, offering a simpler, intent-focused interface. A good abstraction enables developers to focus on the what rather than the how.
For instance, a service named StaticWebsite that automatically configures an S3 bucket, a CloudFront CDN, and a Route 53 DNS record allows a developer to deploy a static site without having to worry about configuring each service individually.
In this context, the role of abstraction is not merely to shield us from the plumbing, but to provide an interface that is understandable, testable, and governable on top of a distributed, asynchronous mesh (Service A, Service B, Service C…).
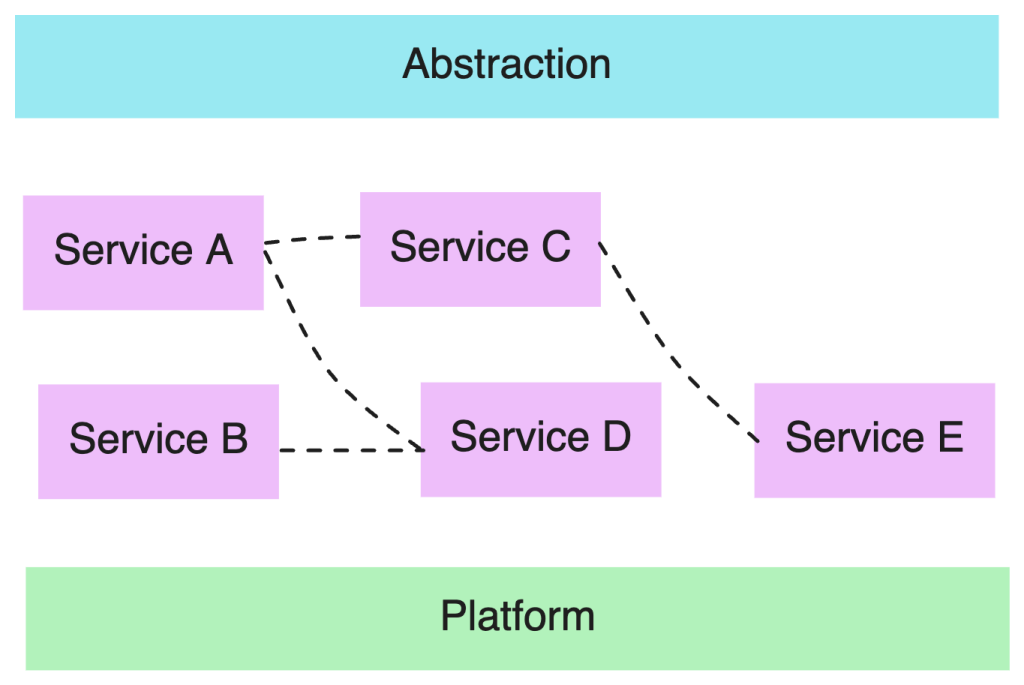
Composing a system by wiring a producer to multiple consumers via a Kafka topic does not guarantee simplicity or interoperability (see the dashed lines in the diagram above). The abstraction introduced by the broker and events is, in fact, intended to reduce cognitive load, make dependencies visible (even in a pub/sub model), and expose business concepts at the right level of granularity. Certain key elements must be put in place to avoid ending up with an implicit execution flow:
- One can reconstruct an overall view using distributed tracing (e.g.
correlationId,span context) and make the event paths explicit through dashboards that correlate logs, metrics, and traces. - Messages should be typed and versioned using an interface contract (structural coupling), with a formal specification of the contracts as provided by tools like AsyncAPI or CloudEvents.
In the search for good abstractions, we must also account for other factors such as asynchrony, which introduces a temporal dimension to message processing messages may expire, propagation delays may occur, and implicit dependencies between tasks may emerge.
To these factors we must add combinatorial effects. With a broker, shared state becomes an illusion, and we find ourselves handling non-deterministic race conditions when multiple services process the same event simultaneously. We therefore need to manage errors that may arise long after the initial emission of an event in a distant service, making it difficult to propagate such errors with their full execution context.
There may be a temptation to guard against this using tests, but testing strategies quickly become heavyweight, requiring tests both upstream and downstream of event emission and consumption, along with the need to simulate message injection and transmission delays in integration tests.
We quickly drift into a zone where uncontrolled theoretical complexity renders the system unpredictable. I can’t help but draw a parallel with cellular automata, which I explored during my studies where simple rules can lead to complex, emergent behaviour.
In EDA, the same principle applies: simple interactions between components can lead to…

Game of Life animation in p5.js. Image courtesy of Hailey Mah
As the system grows and combinatorial interactions explode, controlling it becomes increasingly difficult. Ideally, events should be orthogonal that is, independent but in practice, they often interact either implicitly or explicitly, which undermines modularity and system comprehensibility.
To this, we can add another layer: the human and organisational factor, which inevitably influences how topics are designed, named, and structured. As Conway’s Law famously states:
Any system designed by an organisation will reflect the communication structure of that organisation.”
In other words, technical boundaries including how event interfaces are modelled will almost always mirror existing silos, teams, or flows of responsibility. Untangling this is part of the day-to-day work.
In such an organisational context, a principle I often like to promote is Brooks’ Law:
Adding manpower to a late software project makes it later.”
Brooks’ Law highlights that the more developers involved, the harder it becomes to coordinate efforts, and the more likely we are to drift into a high-dimensional space.
Event transformations including mediators, format conversions, or mappings can become complex, fragile, and difficult to maintain if not properly abstracted or documented. Layering these transformations risks losing context or semantics, leading to bugs that are hard to diagnose.
Maintaining business invariants such as transactional consistency, execution order, or idempotent processing across a distributed, asynchronous architecture is a significant source of complexity and error.
This is what we refer to as the curse of dimensionality.

I don’t see many options for containing the system’s entropy other than:
- Limiting the types of events exposed, even if it means grouping several events together much like aggregates in Domain-Driven Design in order to create more abstract event schemas that align with business concepts rather than exposing technical details.
- Enriching events with contextual metadata (for observability or semantic clarity).
In certain use cases, the order in which events are consumed is not merely desirable it’s fundamental for ensuring business consistency. This necessitates the implementation of specific ordering control mechanisms.
Let me take a deliberately simple example:
A cloud provider wishes to expose virtual machine (VM) state transitions through structured business events:
VM_CREATED: the machine is provisioned (resource reservation, IP assignment, etc.)VM_STARTED: the hypervisor confirms the VM is up and runningVM_STOPPED: the machine has been shut down
These events may be consumed by a range of services (admin console, billing engine, IAM system for permissions, etc.) that rely on the temporal sequence of states to function correctly.
In this scenario, the expected logical sequence is: CREATED → STARTED → STOPPED
Now consider the billing engine as a consumer. Billing should begin when the resource becomes truly active (STARTED) and end when it is shut down (STOPPED).
So what happens if, due to desynchronisation or network latency, the consumer receives events in the following order:STOPPED → STARTED → CREATED?
This semantic inversion would render the billing logic incoherent. Billing operations are not commutative; they must be applied exactly in the order in which they occurred.
Conversely, some services can easily tolerate an unordered event stream. Take, for instance, a module that adds labels to VMs. This service simply writes or updates a piece of metadata and doesn’t require awareness of the machine’s state.
To avoid duplicates, it relies on an idempotency key (e.g. {aggregateId, eventId}):
aggregateId: a stable identifier for the VM, usually a UUIDeventId: a unique identifier for the event
If a message with the same key is received more than once, or out of order, the consumer recognises it, ignores it, or reorders it using timestamp or sequence information. The final result remains correct without needing to impose global ordering.
To support this model, here are some practical strategies:
- Segment the global event stream into logical partitions by business aggregate. Events tied to a single entity will be processed sequentially, ensuring local ordering. Kafka, for instance, supports this kind of logical partitioning and guarantees that all events for a given aggregate arrive at the same consumer in order.
- Implement local buffering mechanisms to reorder events by timestamp or sequence number prior to processing.
- Include logical timestamps (e.g. vector clocks or sequence numbers) within the event payload, allowing consumers to reliably infer causal ordering despite network variance.
It’s clear that EDA is not optimal for these kinds of use cases. These additional requirements introduce a degree of operational complexity.
That’s why, when event ordering is required to ensure business integrity, I would favour using a workflow orchestrator (such as Temporal, Camunda, Zeebe, or Activiti).
Returning to the billing process example, the workflow orchestrator allows you to define the full lifecycle of a virtual machine step-by-step from creation to operation to shutdown.
This form of orchestration is blocking by nature, but at least it guarantees business consistency by pausing progression until the current step has been validated.
By contrast, in EDA, business integrity controls are distributed, partially asynchronous, and difficult to coordinate globally particularly for rollback and compensation logic.
The distinction between orchestration and choreography opens up broader questions, not just in terms of design but also in terms of flow governance.
I felt it was important to introduce the notion of an orchestrator here to illustrate, using the billing example, that business needs should drive the choice of solution and paradigm.
Operational Complexity
To better address the operational challenges specific to event-driven architectures, I’ll now provide an overview of how a system like Kafka works under the hood.
This will serve as the foundation for the next section of the article.
Kafka Fundamentals: A Recap
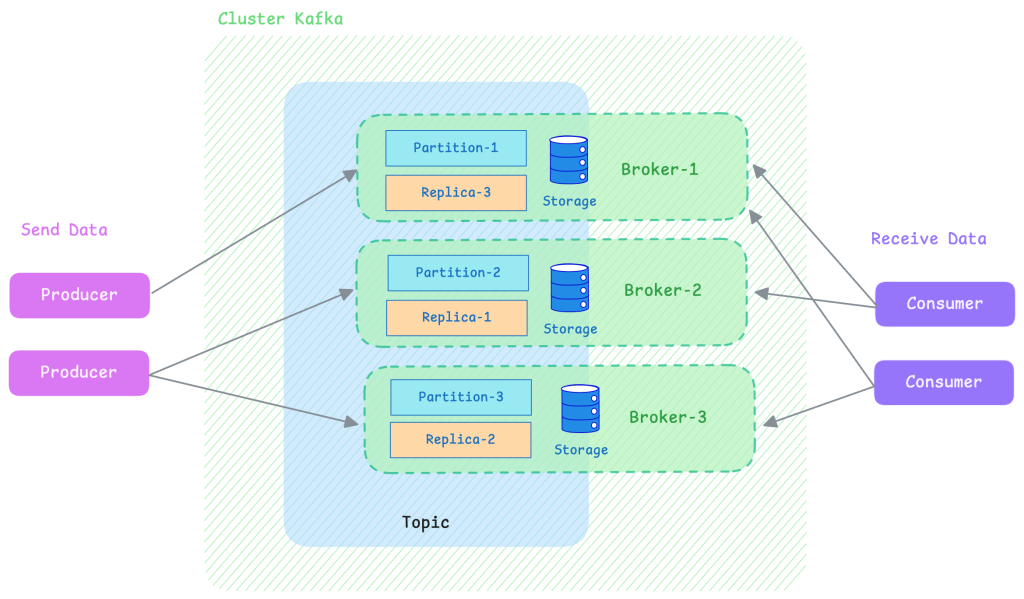
Producer
A component responsible for publishing messages to Kafka. It sends data to one or more topics according to business logic.
Consumer
A component responsible for reading messages from Kafka and performing an action accordingly (e.g. storage, business processing, alerting…).
Offset
Each consumer keeps track of its position in a partition (the offset) to resume reading from the correct point after a restart or failure. This helps ensure no data is lost on the consumer side as long as messages are still retained.
Broker
A Kafka server that handles storing messages on disk. Messages are retained for a configurable period, allowing consumers to replay or catch up if needed.
Kafka Cluster
A group of multiple brokers (and other technical components, which fall outside the scope of this article). It ensures the system can scale and remain highly available.
Topics and Partitions
Data is organised by topic (which reflects business context). Each topic is then divided into partitions, which allow data to be distributed across multiple machines.
Why partitions?
Because it’s rarely a good idea to store all data on a single machine. Partitions enable parallelism and horizontal scalability.
Leader
Each partition has a leader broker, which is responsible for managing the primary copy of the partition. Kafka also maintains backup copies (replicas) of each partition on other brokers.
Replication
Messages in a partition are replicated across multiple brokers. This ensures fault tolerance:
What happens if a broker fails?
Another broker takes over.
A Solution with Limits
Tight Coupling Between Compute and Storage
In Kafka, each broker manages its partitions and associated data locally. This leads to strong coupling between compute capacity and storage:
- Adding a broker requires redistributing partitions, which can involve the massive relocation of data.
- The rebalancing process is I/O-intensive (network and disk), time-consuming, and impacts production performance.
High Costs from Storage and Replication
Kafka’s model is based on local partition storage, with replication by default across three nodes. This entails:
- Significant storage costs, especially when using SSDs.
- Increased network overhead when replicating data across multiple availability zones.
When you factor in replication, the reserved free space needed for operational safety, and the desire to maximise IOPS (input/output operations per second) through high-performance storage choices, the effective cost becomes substantial…
Added to that is the complexity and slowness of Kafka rebalancing, which limits the ability to scale dynamically. As described in this Redpanda guide, it leads us to over-provision resources in advance.
Tiered Storage
Tiered storage was introduced to help Kafka manage large data volumes while reducing storage costs. The idea is to keep recent (“hot”) data on fast local SSDs and move older (“cold”) data to cheaper object storage solutions like S3 or HDFS.
However, this introduces new challenges. Integrating a secondary storage tier adds additional failure points, with potential issues around latency, data consistency, or network connectivity when accessing remotely stored data.
Kafka offers three main retention strategies, adaptable to business needs:
- Infinite retention, where all messages including historical versions of the same key are stored indefinitely in the logs. This preserves full history but can eventually exhaust disk space as log files grow.
- Time- or size-based retention, where messages are automatically deleted after a certain duration or once the log exceeds a configured size. This is a classic approach that limits storage use but sacrifices completeness of history.
- Topic compaction, where Kafka retains only the latest value for each key. If multiple messages refer to the same key, only the most recent is kept. This is useful for maintaining a current view per key like a registry of up-to-date records. However, this strategy is incompatible with tiered storage in Kafka.
As we can see, some of the evolutions introduced to simplify Kafka’s usage end up adding new layers of operational complexity. As is often the case in software engineering, we stack solutions that create new problems and then respond by adding more abstraction layers, which themselves introduce further complexity.
Future Directions and Structural Limits
I recently came across the proposal for “diskless topics” (KIP-1150), which signals that the Kafka community is exploring more radical, cloud-native directions. This proposal aims to write messages directly to object storage, removing the dependency on local storage and inter-broker replication.
It’s still unclear how this approach fundamentally differs from systems like Apache Pulsar, which already follow a similar model.
I also found an insightful article by Gunnar Morling (engineer at Confluent), where he shares thoughts on what Kafka might look like if it were rebuilt from scratch: [What If We Could Rebuild Kafka From Scratch?].
Other alternatives exist, such as BufStream, but like any implementation that maintains Kafka protocol compatibility, it inherits some of Kafka’s structural limitations particularly those that KIP-890 (Transactions Server-Side Defence) aims to address, and which BufStream has also inherited.
Design Considerations for Infrastructure Components
Choosing the right infrastructure components raises a number of conceptual questions:
- How many partitions per topic and per broker can we support without overwhelming memory or CPU?
- How do we balance partitions efficiently?
- Do I have the right ACL configuration to restrict topic access appropriately?
- What level of delivery guarantees do I need (at-most-once, at-least-once, exactly-once)?
- How do I ensure persistence in the event of a crash (replication, backups)?
Conclusion
The goal of this article was not to ban the use of a broker, but rather to encourage selecting a level of sophistication that matches the real needs and, above all, to explicitly address the system’s critical properties, as discussed throughout the article, in order to guide meaningful architectural decisions. There are, in fact, multiple alternatives to the EDA approach for handling asynchrony:
- Using callbacks (deferred synchrony), where the producer provides a callback function to the consumer, which is invoked at a later point.
- Using polling, where a consumer regularly queries a data source to retrieve new data. In the end, this is similar to what a broker consumer does, but with less overhead since the broker typically handles many additional features: back-pressure, persistence, offset tracking…
- Using shared in-memory structures in standalone solutions like Redis Streams, which has recently returned to an open-source licence (AGPLv3).
On that note, I’ll link back to my earlier article, which ties into a broader reflection on the evolution of open-source strategies: Compte rendu libre au lab.
The NATS project is also currently undergoing heated discussions: Looking Ahead with Clarity and Purpose for NATS.io. - Outbox pattern
Ultimately, business logic should drive technical decisions not the other way around.
Every broker whether Kafka, NATS, Pulsar, BufStream, etc. offers different abstractions: topics, partitions, transactions… These are important technical choices, of course, but they must serve the domain, not dictate it.
What truly matters is designing clear and well-modelled business workflows, understanding precisely who produces what data, for what purpose, and in which context.
An event-driven approach only holds value if it enables the expression of intentions aligned with the domain language.
Deploying a broker is within reach for most technical teams.
What sets apart its integration as a meaningful architectural element is the team’s ability to introduce it in a way that fits business needs avoiding unnecessary overengineering, and remembering that every abstraction comes with a cost, whether technical, operational or cognitive.
I’ll end with a literary reference to the book À bouts de flux, which reminds us how our supposedly “resilient” systems are, in reality, built on a fragile web of hidden dependencies.
The digital world, which we perceive as immaterial and autonomous, is inseparable from a network of physical, electrical, logistical and energy infrastructures where even minor failures can trigger cascading effects.
In my view, this line of thinking naturally extends to event-driven architectures, and more broadly, to how we design systems today.